Pydantic 1 vs 2: A Speed Comparison
August 18, 2023 python pydantic performance ☕️ buy me a coffee
Back in 2022 I did a comparison of some of the most well known python data class libraries in various categories. In this blog post I came to the conclusion that pydantic was only apt for less performant applications. However, with the release of Pydantic v2 in late June of 2023 touting 5-50x speed improvements compared to v1 due to a rewrite of the core logic in Rust.
So in the face of these new claims, lets put it to the test.
Experimental Setup
My workload hasn’t changed much since the last post, so I will still have a simulation based approach.
I made two very simple data types. Coord relies on purely python native types, and Coords holds a list of the Coord type.
class Coord(pydantic.BaseModel):
x: float
y: float
z: float
heading: float
tag: str
idx: int
class Coords(pydantic.BaseModel):
coords: list[Coord]
We create the $N$ length data using the same seed to ensure it’s an apples for apples comparison across the versions.
def create_data(N=10,seed=1)
rng = np.random.default_rng(seed=seed)
positions = rng.random((N, 3)).astype(np.float32)
headings = rng.random(N).astype(np.float32)
idxs = np.arange(0, N).astype(snp.int32)
tags = list(
map(
"".join,
np.array(list(string.ascii_letters))[
rng.choice(len(string.ascii_letters), (N, 100))
],
)
)
return positions, headings, idxs, tags
This is then used to instantiate $N$ classes of Coord which is then used to instantiate one class of Coords with
def run(positions, headings, idxs, tags):
coords = []
for position, heading, idx, tag in zip(positions, headings, idxs, tags):
x, y, z = position
coords.append(Coord(x=x, y=y, z=z, heading=heading, idx=idx, tag=tag))
return Coords(coords=coords)
Every loop of this function is timed using time.perf_counter_ns.
Performance
We start by comparing the performance from $N=1$ to $N=100$ (with $100$ repeats at every $N$) as seen below in the figure.
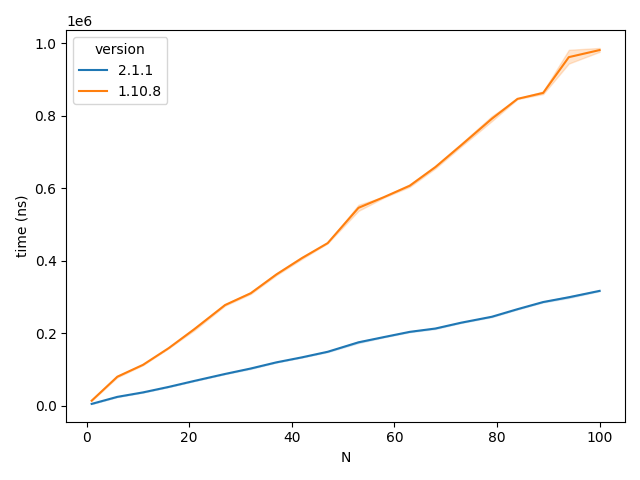 Time taken to instantiate the data classes by Pydantic version
Time taken to instantiate the data classes by Pydantic version
Evidently the claims are accurate! v2.1.1 is substantially faster than v1.10.8 over all data points with both seemingly having an $O(n)$ relationship.
To give Pydantic something more to chew on, we’ll feed it data types that it’ll have to convert. We’ll simply pre-emptively convert float to int and vise-versa. Not the hardest task in the world but interesting nonetheless as this occurs often in my workflows.
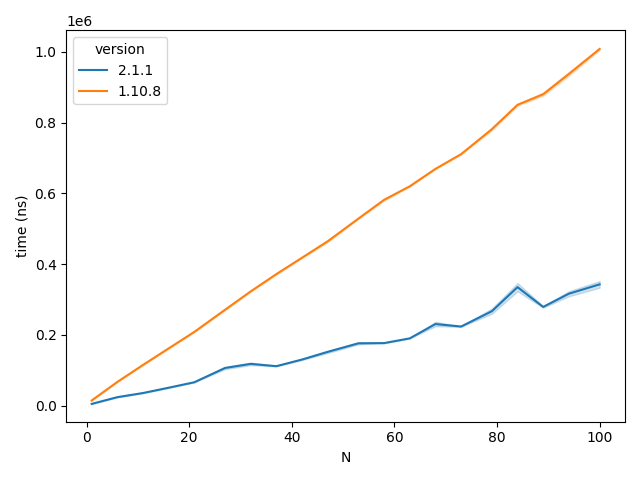 Time taken to instantiate the data classes by Pydantic version with incorrect (but castable) data types
Time taken to instantiate the data classes by Pydantic version with incorrect (but castable) data types
Inpsecting the above graph, this has slightly slowed down both versions but not by much.
Final Thoughts
Given that the Pydantic team have taken the time and effort to rewrite the core of the library in Rust, the results are no surprise. With the massive popularity of libraries like FastAPI and Dynaconf using Pydantic for core functionality, this performance improvement will help the community massively in the form of saving on compute time. However, for cases where type checking isn’t essential, namedtuples and dataclasses are probably still the way to go for raw speed. Nonetheless, I will now consider using Pydantic in more scenarios because of these speed gains and because it’s a bloody brilliant library!
Future Work?
I might redo the analysis undertaken in the afformentioned previous post, with some more suggestions made by my readers:
- pydantic-dataclasses
- atom
- Custom pybind11 objects
- … ?
If this is something you’d be interested in, please let me know in the comments!