Min-Maxing Your First Wordle Guess
February 6, 2022 wordle python ☕️ buy me a coffee
My pal showed me Wordle for the first time the other day and I instantly wanted to know what the objectively best starting guess was. Some may argue that that’s not in the spirit of the game and that it should be a daily challenge, but those people probably don’t spend 45 minutes on their first game (that’d be super awkward right…?).
TL;DR: oreas, arose, seora, aries, arise, raise, serai, aesir
Firstly we need to figure out some heuristic to measure the goodness of a word. The most intuitive would be to pick a word with the most frequently used letters within the set of 5 letter words. Thus, we can measure a words score using
\[p(\textbf w) = \sum^5_{i=0} s(w_i),\]which translates to the sum of the frequencies of each individual letter.
Enough maths. Let’s get into the code.
Next, let’s get a word list. I chose this one because it was the first one I found. Simple. We’ll read this into memory, but only the 5 letter words.
words = []
with open('words_alpha.txt') as f:
for line in f.readlines():
line = line.strip()
if len(line) == 5:
words.append(line)
This results in 15918 possible words. My guess the Wordle backend uses a wordlist similar, if not exact, to this one.
We then need to count all the letters and divide by the total amount of letters to get each letter’s frequency.
big_word = list("".join(words))
letter, count = np.unique(big_word, return_counts=True)
freq = count/len(big_word)
This results in a nice graph with a surprising result.
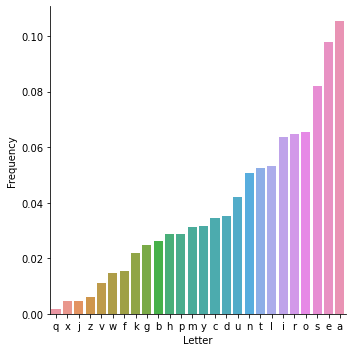 Most frequent letters in the set of all 5 letter words
Most frequent letters in the set of all 5 letter words
a seems to be the most common letter even though it’s a commonly known fact that e is th most used letter in the english language! This is (probably) because we’re limited to the set of 5 letter words, and no all words.
Another optimisation on the quest for the best starting word, is optimising the word to exclude repeating letters. Having skiing, for example, would be a waste of a letter so let’s employ a nifty hack using set.
print(f"{'e'*9}, {len('e'*9)}, {len(set('e'*9))}")
eeeeeeeee, 9, 1
As you can see above, we can easily filter for words that have multiples if the set object containing that word has a length less than 5.
filtered_words = []
scores = []
for word in words:
if len(set(word)) == len(word):
score = np.sum([freq_df.loc[letter] for letter in list(word)])
scores.append(score)
filtered_words.append(word)
And just like that we’ve got a tie for the top word. All of these 8 words use the 5 most frequent letters (a, e, s, o, r).
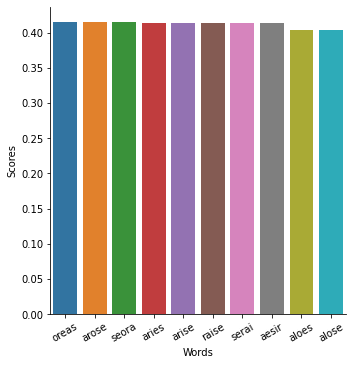 The top 10 objectively best words to use for your first guess in Wordle
The top 10 objectively best words to use for your first guess in Wordle
❗ Disclaimer - I am terrible at this game, and these words might be terrible too for various reasons. Use at your own risk.